
The Best 8 Dynamsoft Document Capture Alternatives
-
-
 13 Like
13 LikeOnline OCR
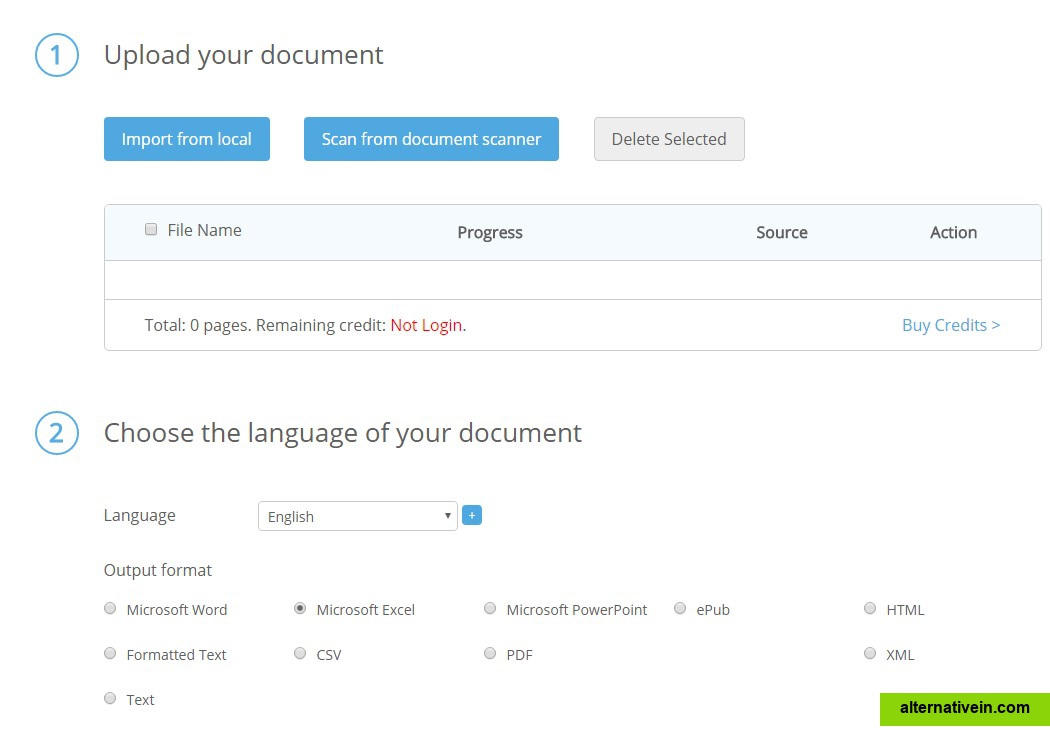
Free Online OCR is a software that allows you to convert scanned PDF and images into editable Word, Text, Excel output formats.
-
-
 5 Like
5 LikeFree-OCR.com
Free-OCR.com is a free online OCR (Optical Character Recognition) tool. You can use this service to extract text from any image you supply. This service is free, no...
-
-
3 Like
NewOCR.com
NewOCR.com is a free online OCR (Optical Character Recognition) service. NewOCR.com can analyze the text in any image file that you upload, and then convert the text...
-
